從HTML網頁擷取出需要的資料後,可以將整理好的資料儲存成檔案。常用的檔案格式有兩種,分別為CSV和JSON檔。
CSV檔案:
其檔案內容是使用純文字來表示表格資料,是一種文字檔案。表示法為每一行是表格的一列,每一欄位用”,”逗號來分隔。
範例.
Math | English | Science
------------- | -------------
90 | 75 | 80
35 | 85 | 60
CSV格式: Math, English, Science
90, 75, 80
35, 85, 60
JSON檔案:
是一種類似XML的資料交換格式,只有文字內容。其表示法為大括號定義成對的鍵和值,使用” : ”分號分隔,資料間使用”,”逗號分隔,定義物件使用” { } ”大括號,定義正列使用” [ ] ”方括號表示。
範例.
{
“teacher” : “林老師”,
“students”: [
{ “name” : ”陳方方”, “student_id” : “409123456” },
{ “name” : ”許正正”, “student_id” : “409134567” },
{ “name” : ”蔡圓圓”, “student_id” : “409145678” },
]
}
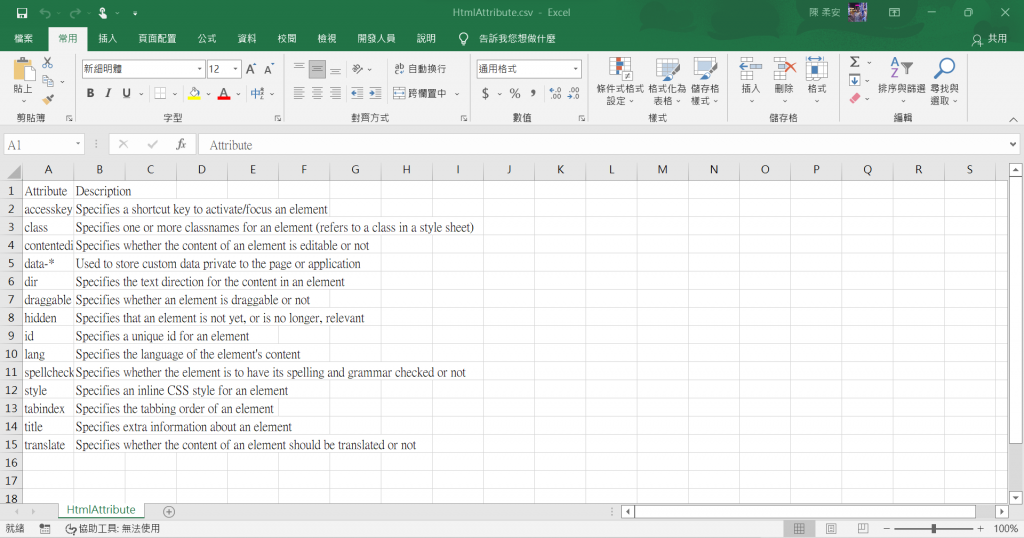
從W3Shool網站取出表格資料寫入CSV檔案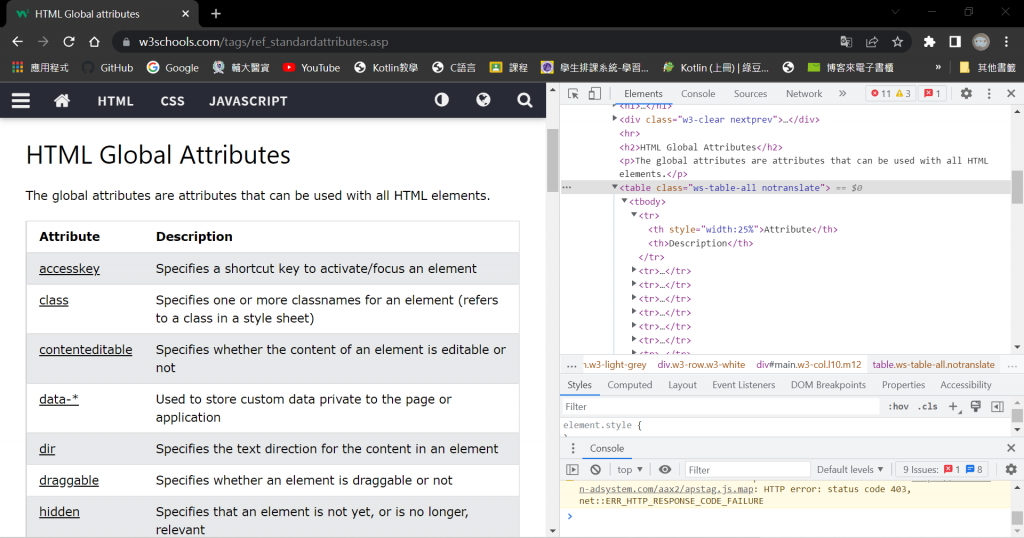
import requests
from bs4 import BeautifulSoup
import csv
url = "https://www.w3schools.com/tags/ref_standardattributes.asp"
csvfile = "HtmlAttribute.csv"
r = requests.get(url)
r.encoding = "utf8"
soup = BeautifulSoup(r.text, "lxml")
tag_table = soup.find(class_="ws-table-all notranslate") # 找到<table>
rows = tag_table.findAll("tr") # 找出所有<tr>
# 開啟CSV檔案寫入截取的資料
with open(csvfile, 'w+', newline='', encoding="utf-8") as fp:
writer = csv.writer(fp)
for row in rows:
rowList = []
for cell in row.findAll(["td", "th"]):
rowList.append(cell.get_text().replace("\n", "").replace("\r", ""))
writer.writerow(rowList)


 iThome鐵人賽
iThome鐵人賽